Ladislas Nalborczyk
Postdoctoral researcher
Cognitive neuroimaging unit, NeuroSpin, CEA
PICNIC team, Paris Brain Institute (ICM)
Research interests
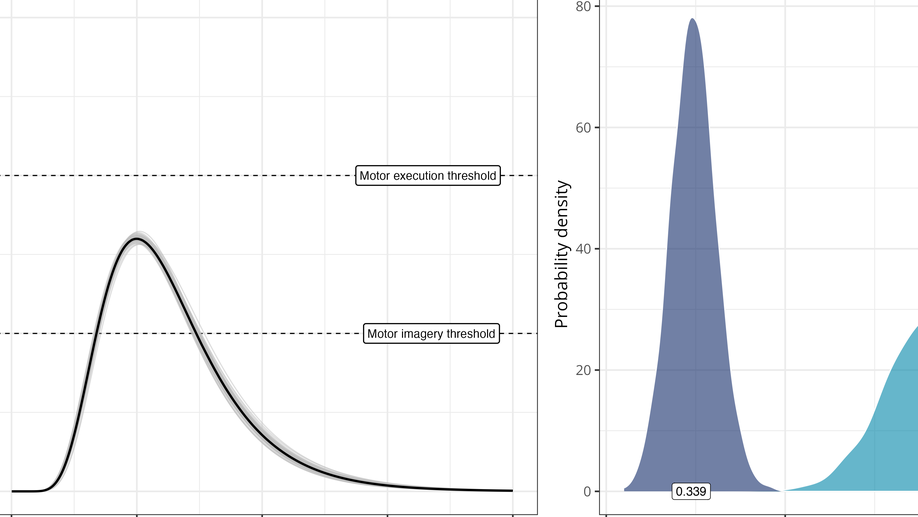
Mental production of speech (inner speech)
I am a computational cognitive neuroscientist interested in the conscious experience of inner speech and its neural underpinnings. My research combines experimental (e.g., psychophysics, EMG, M/EEG, TMS) and computational (e.g., mathematical modelling, machine learning) methods to understand how complex patterns of neural activity (in both biological and artificial neural networks) give rise to algorithms supporting the mental simulation of speech.
Statistical modelling and slow science
In parallel, I also work on the development and dissemination of rigorous experimental and statistical methods. Besides, I feel very concerned about the issue of making our research more open, reproducible, and sustainable.
Interests
- Inner speech
- Motor control
- Motor imagery
- Time perception
- Speech production
- Psycholinguistics
- Cognitive modelling
- Statistical modelling
Education
-
PhD in Cognitive Psychology, 2019
Univ. Grenoble Alpes
-
PhD in Clinical and Experimental Psychology, 2019
Ghent University
-
MSc in Cognitive Science, 2015
Grenoble Institute of Technology
-
BA in Psychology, 2013
Pierre-Mendès France University